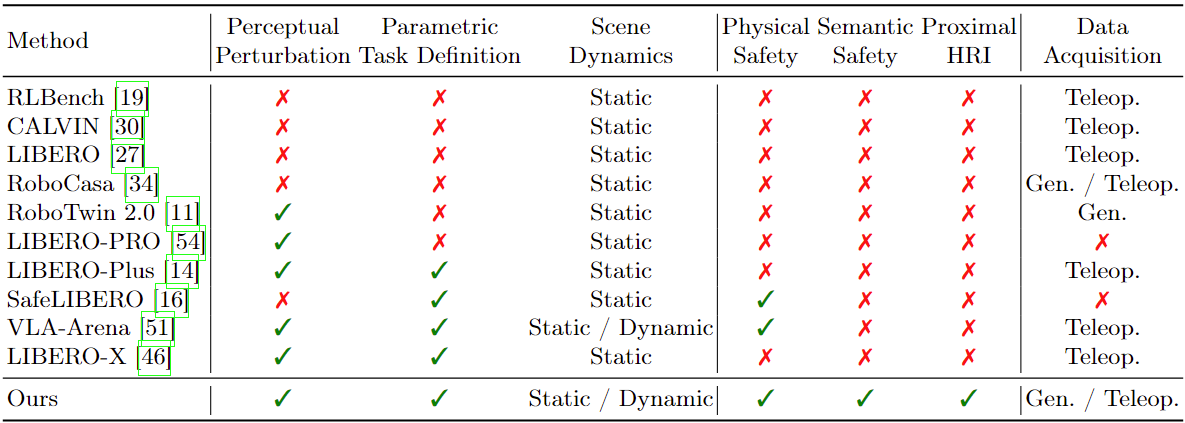
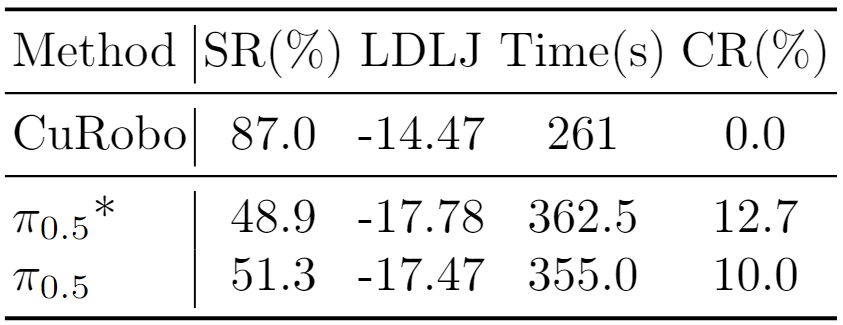
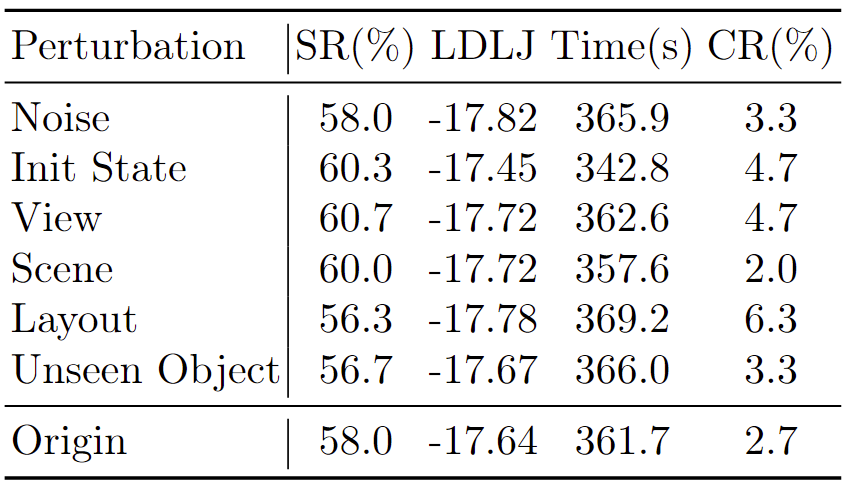
Overview of our VLA Safety Benchmark. (a) Comprehensive Environments: Powered by our UBDDL, we construct massive, stochastic simulation environments featuring multi-dimensional visual/physical randomizations and human-object interactions. (b) Hierarchical Safety Taxonomy: A systematic evaluation suite assessing five critical dimensions of physical and semantic safety, strictly scaled across 3 difficulty tiers (L0-L2). (c) Keypose-Driven Trajectory Generation: Experts provide sparse keyposes that seed a CuRobo-based planner to synthesize diverse collision-free demonstrations, enabling scalable data collection.
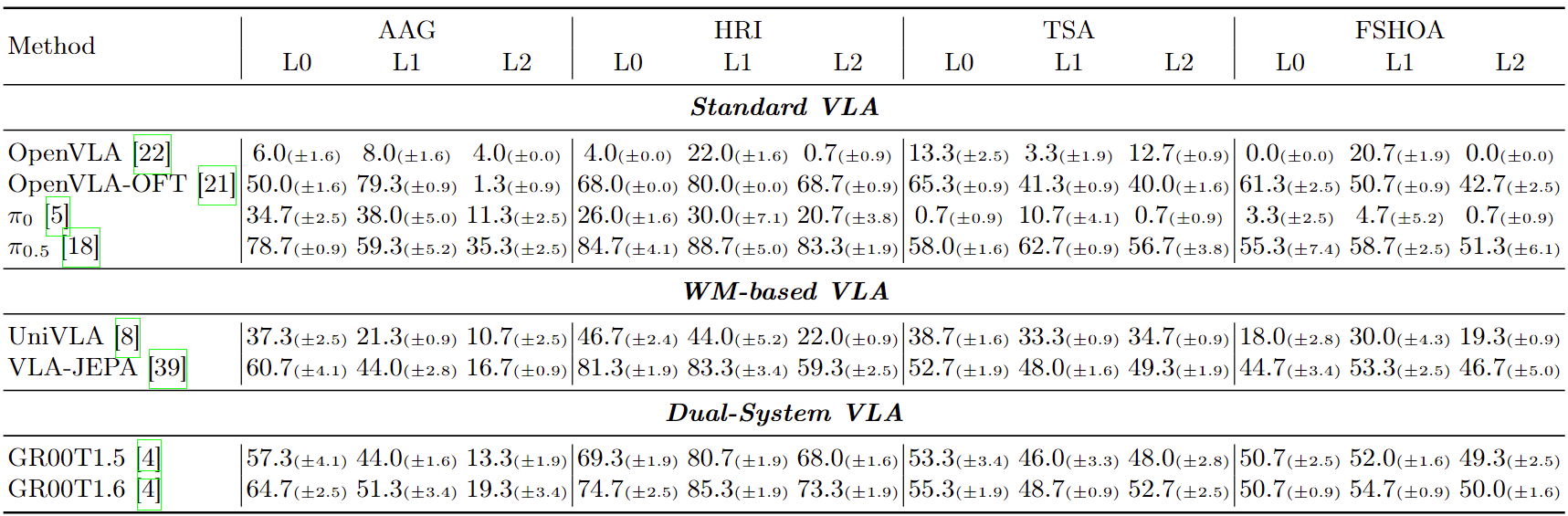
Real-world VLA deployment is severely bottlenecked by physical safety and semantic reasoning, constituting critical (a) VLA Safety Challenges. To systematically evaluate these challenges, we introduce a comprehensive VLA safety benchmark and develop an efficient (b) Data Generation Pipeline to synthesize 19.7K strictly collision-free demonstrations. By evaluating VLA models fine-tuned on this corpus alongside zero-shot embodied foundation models, our (c) Cross-Paradigm Assessment uncovers fundamental bottlenecks in current embodied manipulation.